В ходе тестов выяснил, что на хост ClickHouse генерируется огромная нагрузка на CPU, при том, что остальные ресурсы почти не расходуются. Дополнительные исследования показали, что это возникает из-за запроса с DISTINCT из управляющего дэша. На управляющий дэш вынесено 25-30 фильтров. Запрос с DISTINCT на таком количестве полей даёт очень больште сортировки, которые как раз и “съедают” ресурс CPU. В сессии с вопросами ответами (https://help.luxmsbi.com/-484) прмерно с 07:20 Дмитрий Дорофеев объясняет концепцию построения куба с dictionaries, но нигде нет описания того, как её правильно реализовать.
Прошу скомпоновать описание и примеры того, как необходимо правильно конфигурировать уровень БД и описывать конфигурацию куба, чтобы устранить тяжеловесные DISTINCT-ы к БД из управляющего дэша.
Спасибо.
Добрый день!
Прикладываю тестовый пример с описанием.
1 - Создадим для примера куб postgres.fortests_my_data с полями dic_one, dic_two, dic_three, у которых foreign keys на справочники( postgres.fortests_dic_one, postgres.fortests_dic_two, postgres.fortests_dic_three) соответственно.
2 - В конфиге дименшена , например dic_one куба postgres.fortests_my_data указываем следующий конфиг :
{
"members": {
"default": {
"sort": [
"title"
],
"with": "postgres.fortests_dic_one",
"columns": [
"id:id",
"title:title"
],
"distinct": false
}}}
3 - В таблице и управляющем дэше необходимо использовать один и тот же куб.
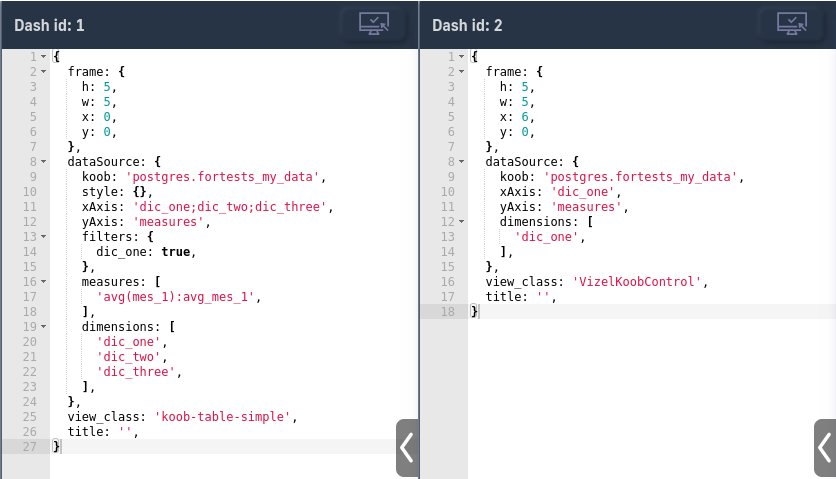
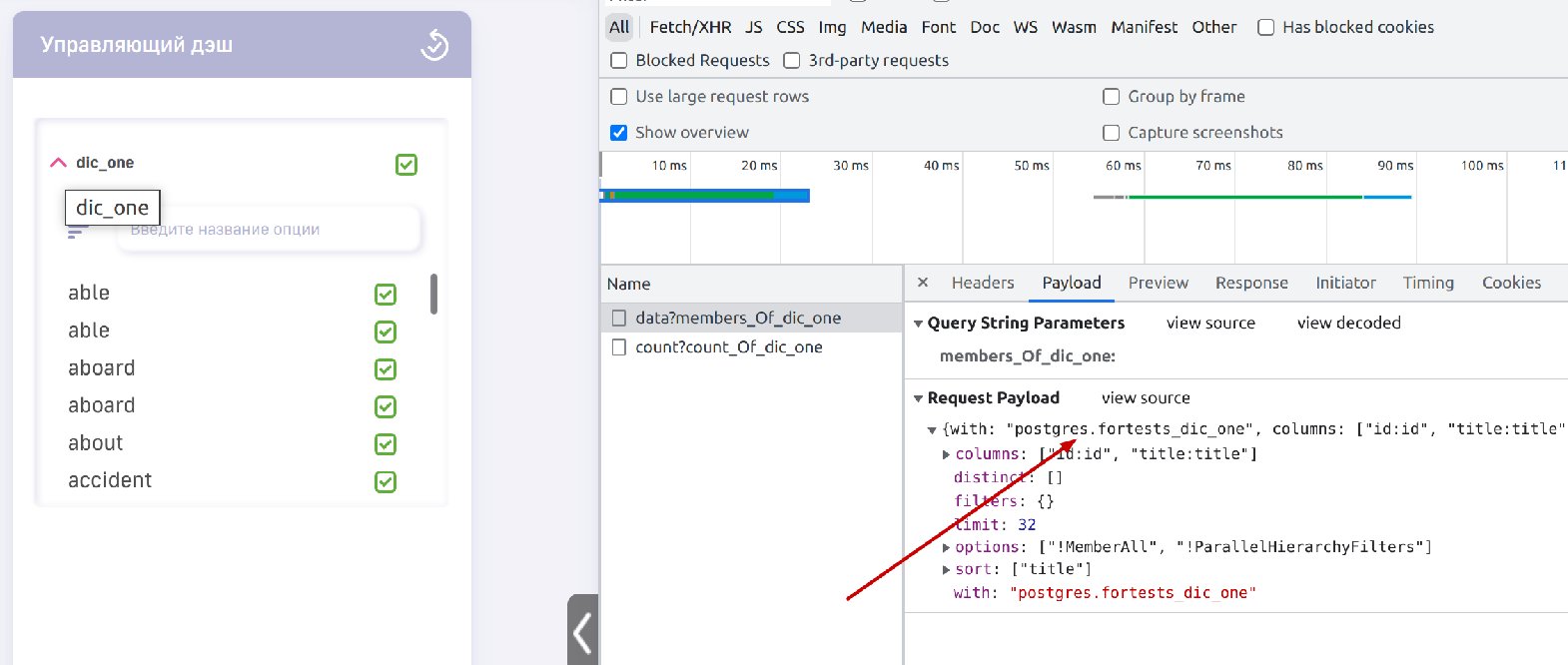
4 - После открытия фильтра в управляющем дэше, запрос будет направлен в справочник :
Спасибо за подробный ответ. После прочтения возникли некотороые вопросы:
1.1. Как правило, на больших объемах данных Foreign Key не делают для ускорения операций вставки/удаления данных. Обязательна ли связь по FK между таблицей фактов и измерениями? Кроме того. ClickHouse DBMS does not have any explicit foreign keys (can you support foreign key? · Issue #9 · ClickHouse/metabase-clickhouse-driver · GitHub).
1.2. В видео звучит определение “dictionary”. В терминах ClickHouse, это можно трактовать как
- объект типа Dictionary (Dictionaries | ClickHouse Docs);
- обычная таблица измерения (Creating Tables in ClickHouse | ClickHouse Docs).
Можно ли прояснить этот момент детальнее?
1.3. Структура таблиц будет иметь примерно такой вид, как я понимаю:
fortests_my_data:
{
ID_dic_one int,
ID_dic_two int,
ID_dic_three int,
measure1 double,
measure2 double
}
И для измерений что-то такого вида:
dic_one:
{
ID_dic_one int,
attr1_dic_one sting,
attr2_dic_one string,
attr3_dic_one sting
}
Правильно ли я понял пример?
1.4. Запрос, который будет храниться внутри куба должен содержать в себе выборку только из таблицы фактов или из таблицы фактов и измерений с построекнием соответствующих связей?
1.5. Вижу, что описывается пример на PostgreSQL. Всё ли из описанного будет применимо к ClickHouse?
2.1. Уточните, данный блок необходимо прописывать в разделе “Конфигурация” у целевого куба?
2.2. Можно ли дать пояснения по предоставленному тексту конфигурации? За что отвечает каждый блок? Как можно модифицировать этот код под разные задачи?
2.3. По примеру не могу сообразить как мне прописать конфигурацию хотя бы для 3 измерений, чтобы они вычитывались из своих таблиц напрямую. Сможете немного расширить пример?
4. Насколько я помню, событие setKoobFilters идентично выставлению фильтра в управляющем дэше. Будет ли поведение дэшборда таким же, как показано на рисунке, при наступлении события setKoobFilters?
Подскажите пожалуйста, в 4-м вопросе, о каком скриншоте идет речь?
Приложите его пожалуйста:
4. Насколько я помню, событие setKoobFilters идентично выставлению фильтра в управляющем дэше. Будет ли поведение дэшборда таким же, как показано на рисунке, при наступлении события setKoobFilters?
Добрый день.
1.1 Нет, связь по FK не нужна
1.3 Да , все верно
1.4 Запрос в целевом кубе содержит выборку только из таблицы фактов. Построение связи между таблицами фактов и измерений не требуется. Для таблиц с измерениями нужно будет создать отдельные кубы, чтобы в дальнейшем сослаться на них в Конфигурации измерений в целевом кубе.
1.5 Да, конфигурация идентична для всех поддерживаемых БД.
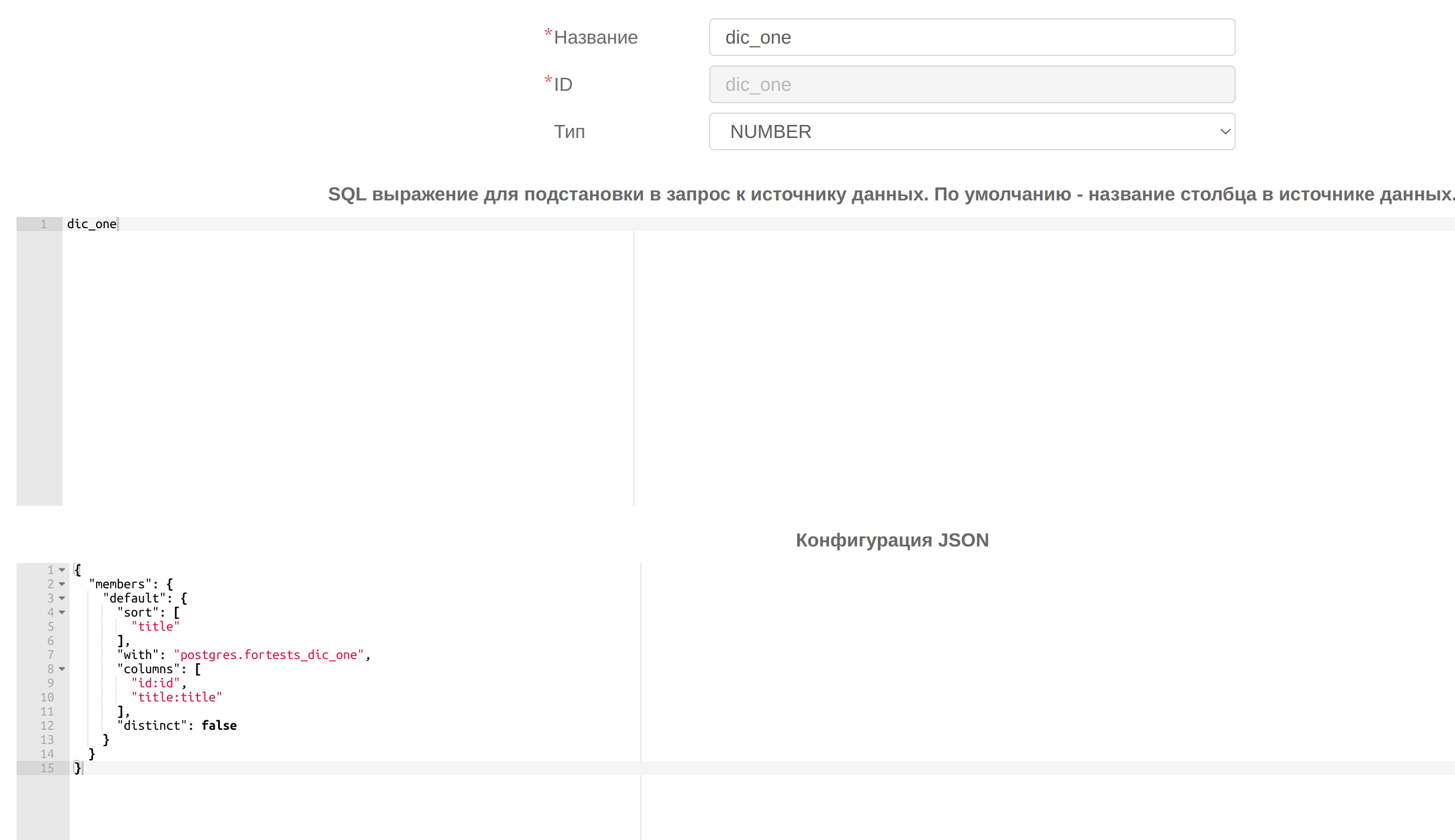
2.1 Данный блок нужно прописывать в Конфигурации измерения(-ий) целевого куба . Например, отталкиваясь от приведенного выше примера конфигурация для измерения dic_one имеет следующий вид :
2.2-2.3 Приведу пример для 3 измерений , которые находятся в 3 разных таблицах-справочниках. В качестве источника данных будет выступать Clickhouse.
ddl для таблиц-справочников:
CREATE TABLE fortests.dic_one
(
`dic_one_id` Int64,
`dic_one_title` String,
`description` String
)
ENGINE = MergeTree
ORDER BY dic_one_id
SETTINGS index_granularity = 8192;
CREATE TABLE fortests.dic_two
(
`dic_two_id` Int64,
`dic_two_title` String,
`description` String
)
ENGINE = MergeTree
ORDER BY dic_two_id
SETTINGS index_granularity = 8192;
CREATE TABLE fortests.dic_three
(
`dic_three_id` Int64,
`dic_three_title` String,
`description` String
)
ENGINE = MergeTree
ORDER BY dic_three_id
SETTINGS index_granularity = 8192;
ddl таблицы с фактом(mes_1):
CREATE TABLE fortests.my_data
(
`dt` Date,
`mes_1` Int64,
`dic_one` Int64,
`dic_two` Int64,
`dic_three` Int64
)
ENGINE = MergeTree
ORDER BY dt
SETTINGS index_granularity = 8192;
, где поля dic_one,dic_two,dic_three в таблице fortests.my_data хранят числовые значения , соответствующие значениям в полях (dic_one_id,dic_two_id,dic_three_id) в таблицах-справочниках
Создадим кубы для таблицы с фактом и измерениями (click.fortests_my_data) и для таблиц-справочников (click.fortests_dic_one,click.fortests_dic_two,click.fortests_dic_three). Для измерений(dic_one,dic_two,dic_three) в целевом кубе (click.fortests_my_data) укажем следующие конфигурации:
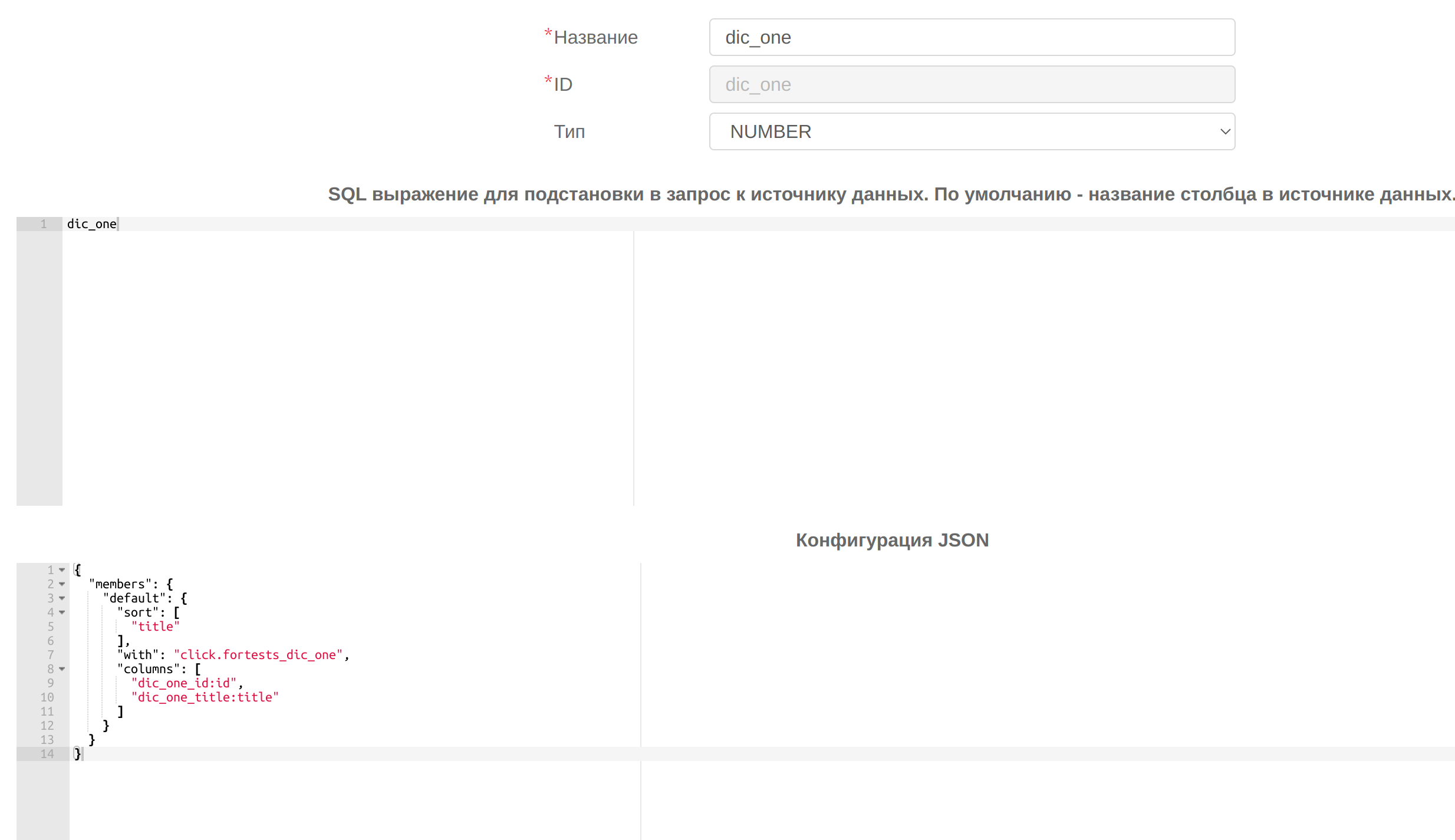
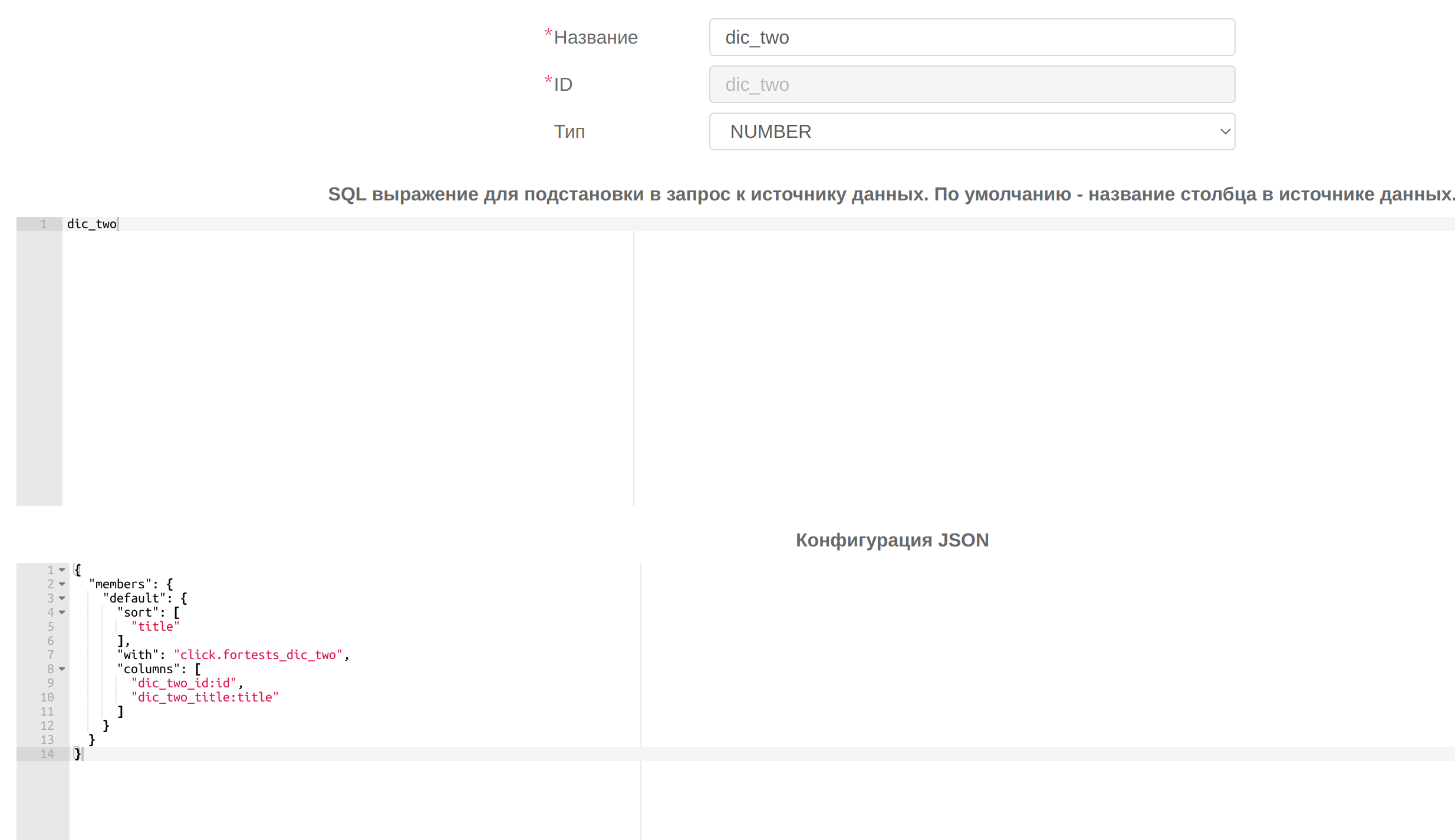
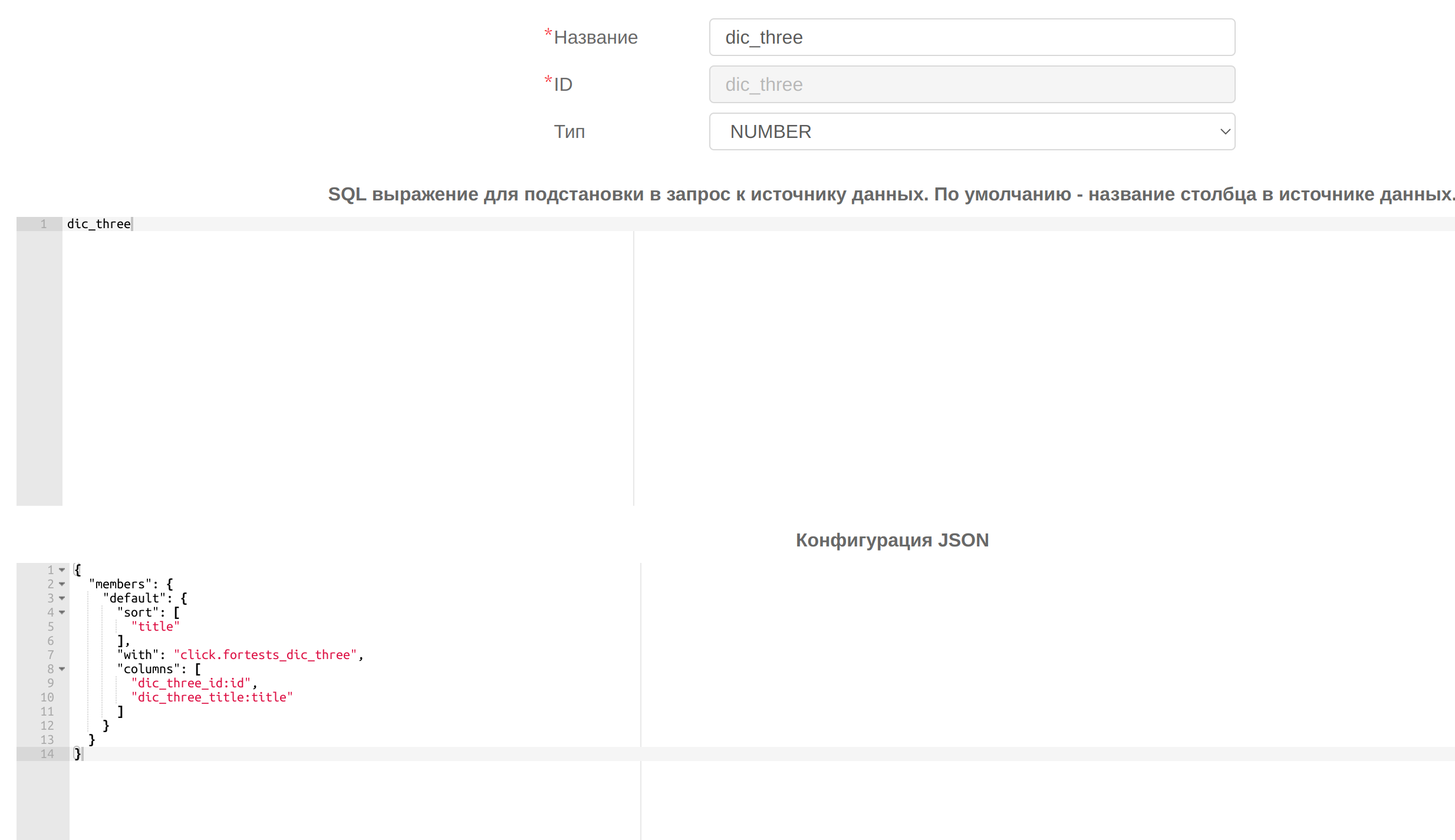
, где в поле sort указывается по какому полю(id или title) будет произведена сортировка, в поле with указывается id куба соответствующего справочника, в поле columns массив строк в следующем формате:
"имя_поля_с_числовыми_id_из_справочника:id",
"имя_поля_со_значениями_для_измерения_из_справочника:title"
id и title aliases, которые используются для создания связи на стороне веб-клиента.
Далее создадим, для примера, пару дэшлетов(таблица и управляющий дэш) используя куб click.fortests_my_data
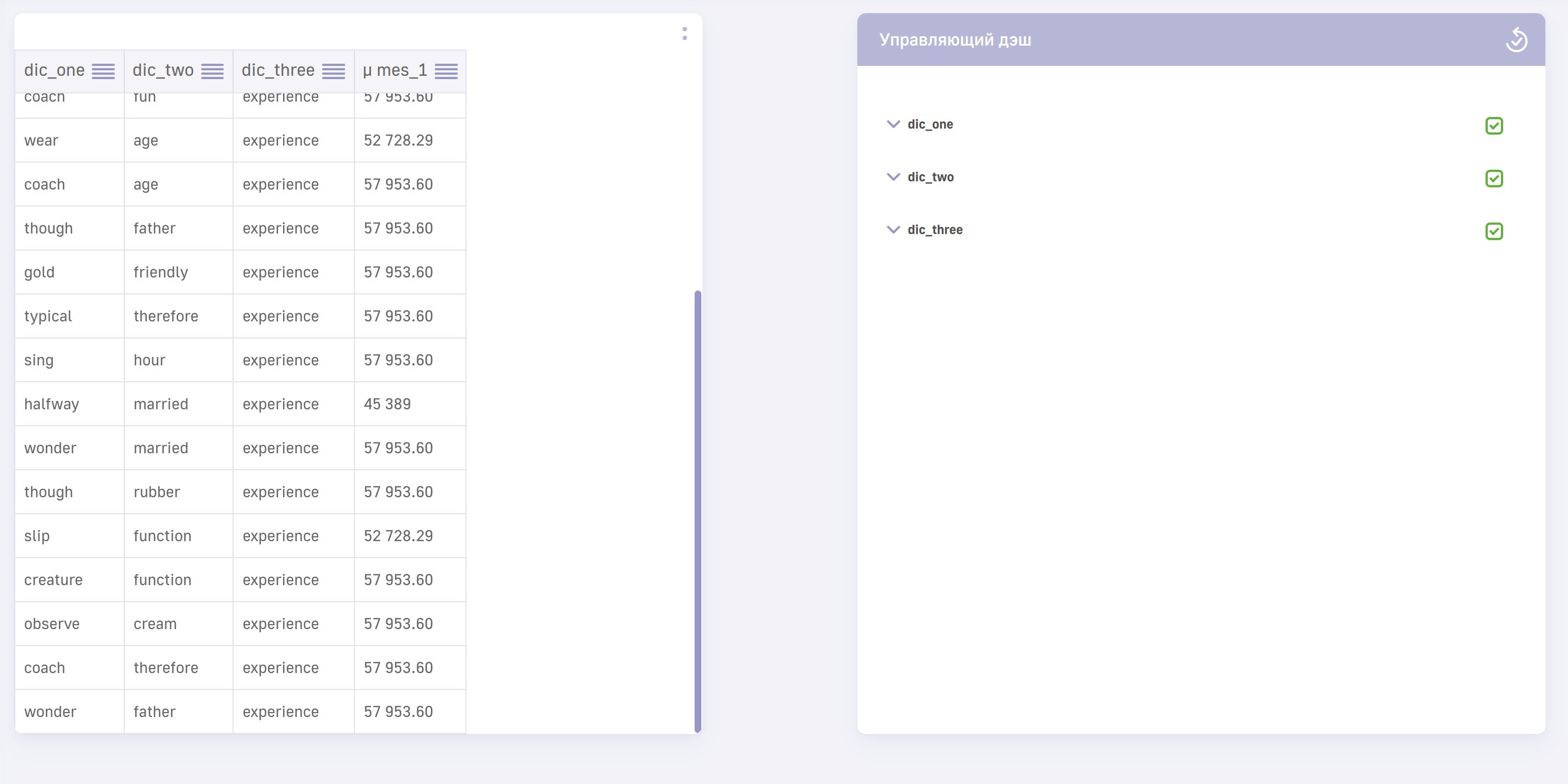
При открытии фильтра в управляющем дэше запрос уходит в таблицу-справочник
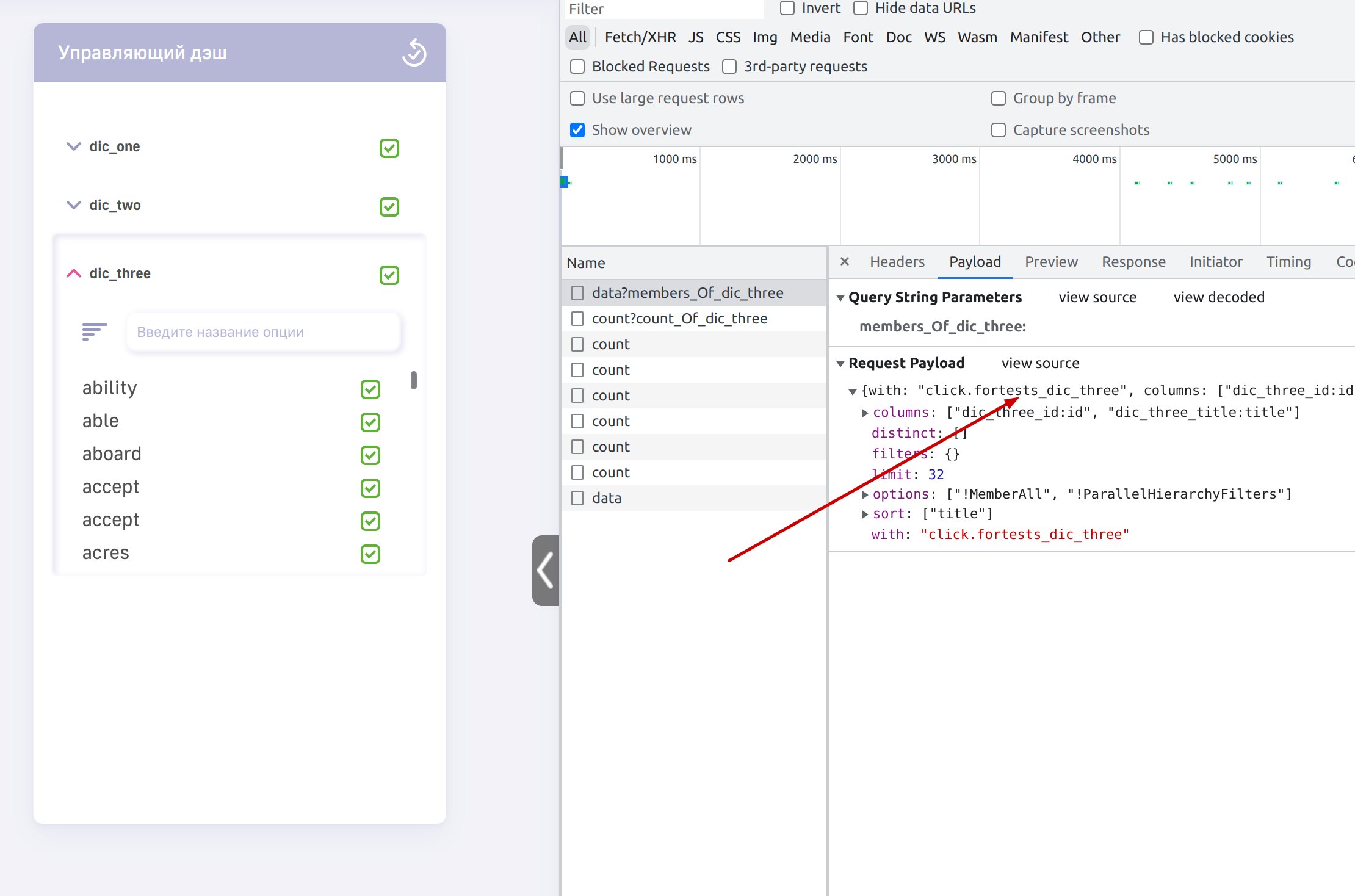
Большое спасибо за очень подробную инструкцию.
Начал собирать данные по приведённому примеру, возник вопрос, правильно ли я понимаю концепцию.
Вижу, что в конфиге указывается id и title. По сути, key/value пара. Эта пара привязывается к id из таблицы фактов. Получается, что на один id из таблицы фактов можно извлечь только один атрибут измерения. Как правило, в измерении больше одного атрибута.
Вопросы:
- Правильно ли я понимаю, что если я хочу присоединить N атрибутов измерения к таблице фактов, то потребуется сделать N колонок с одинаковым id, каждый из которых будет привязан к своему атрибуту измерения?
- Ключ “distinct”: false/true относится к id или к title? Как будет меняться поведение выборок в зависимости от данного ключа? Выставляю ключ хоть в true, хоть в false, но value при этом не становятся уникальными. Например, так:
.
3. Есть ли еще какие-либо дополнительные ключи кроме “distinct”?
4. Наследуется ли тип и свойства title? Что будет, если, например, для fortests.dic_one.dic_one_title будет выставлено “hierarchyType”: "parallel? Или потребуется прописывать данный атрибут уже непосредственно в кубе fortests.my_data.dic_one? Если да, то как?
Добрый вечер.
- Если в вашей таблице-справочнике содержится N-ое количество атрибутов , то на каждый из атрибутов вы можете в целевом кубе добавить размерность
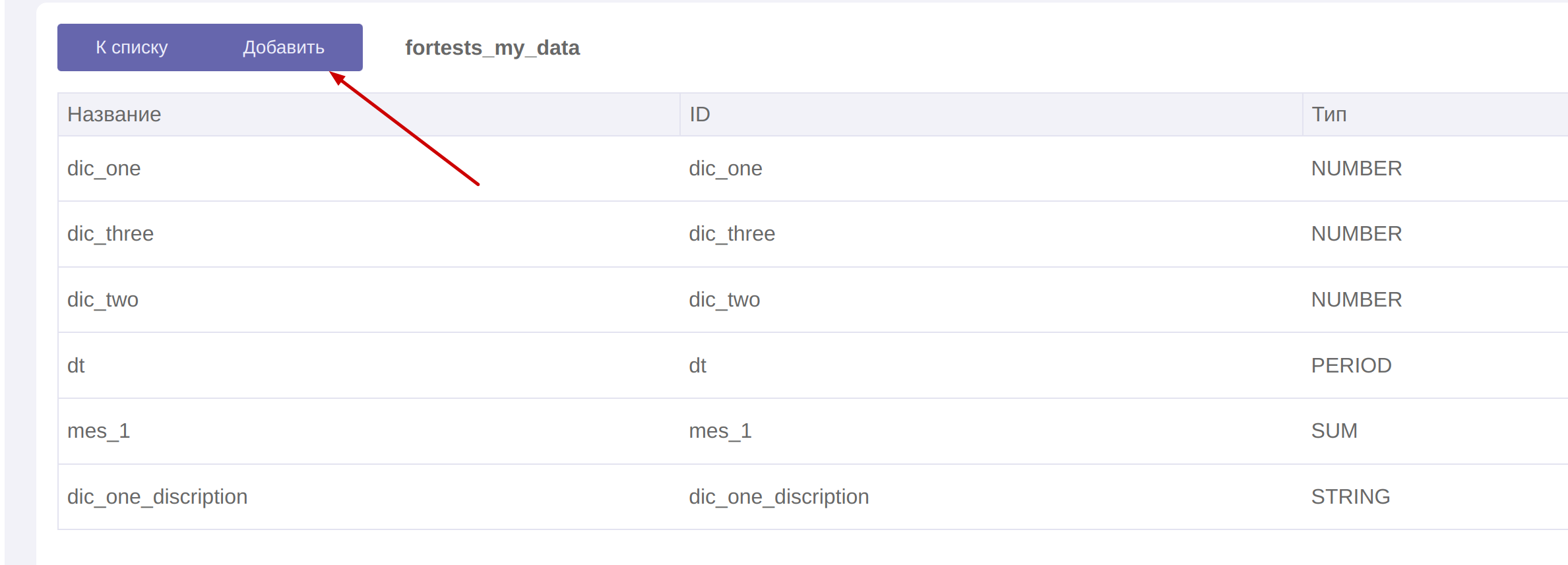
Указав название,id . В поле Sql выражение… подставьте поле, по которому происходит маппинг с таблицей справочником(в примере идет маппинг с таблицей fortests.dic_one по полю dic_one, которые были использованы в примерах выше)
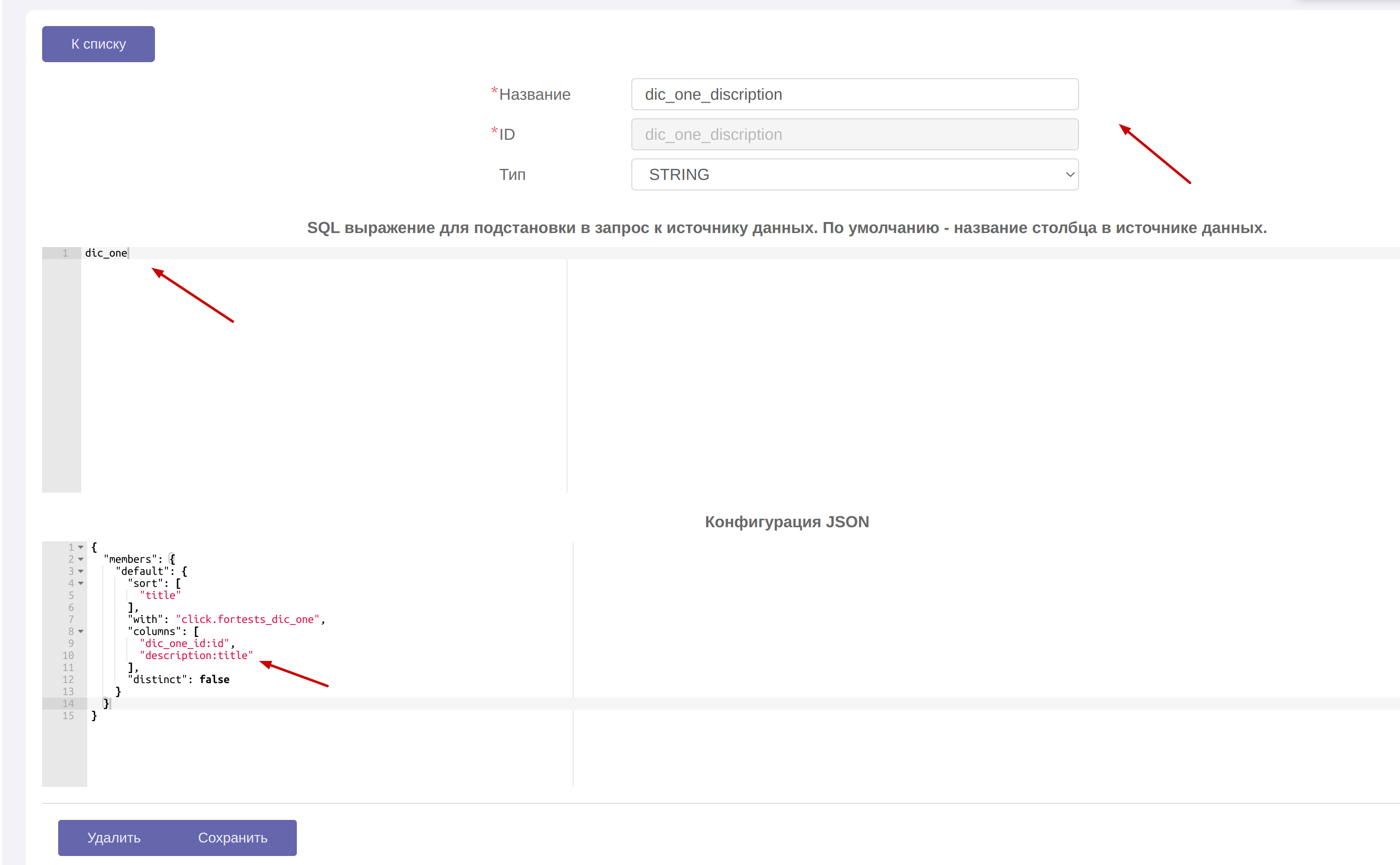
Поле конфигурация JSON заполнить по примеру из предыдущего ответа:
в массив columns вносятся значения исходя из следующего:
"имя_поля_с_числовыми_id_из_справочника:id",
"имя_поля_со_значениями_для_измерения_из_справочника:title"
В данном примере мы выводим атрибут description измерения dic_one
Далее мы можем использовать эту размерность на дэшлетах:
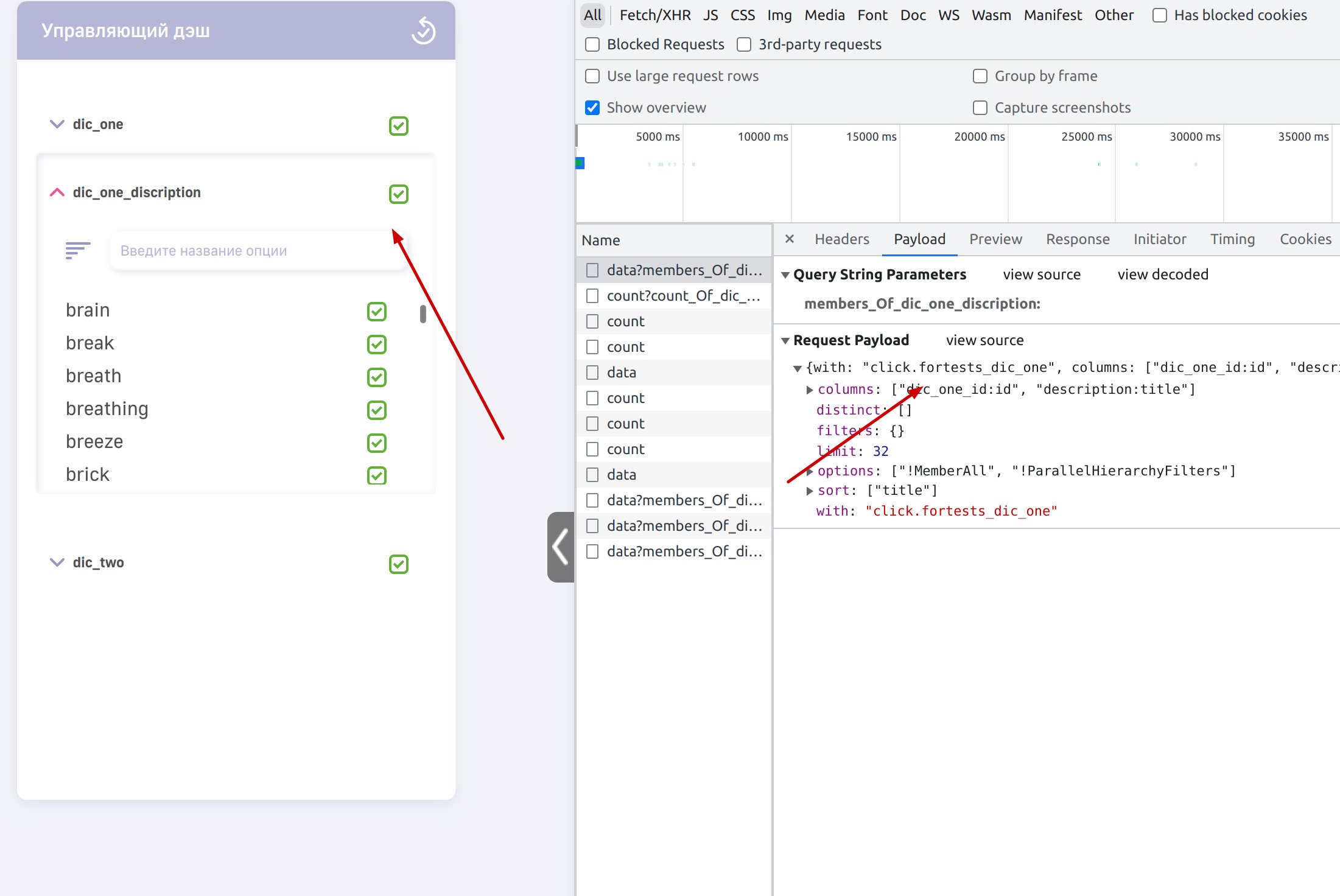
2 Относится к паре id, title (В бд уходят подобные запросы select distinct my_id as id, my_title as title from …)
- Спасибо, интересный способ. В этом вопросе разобрался.
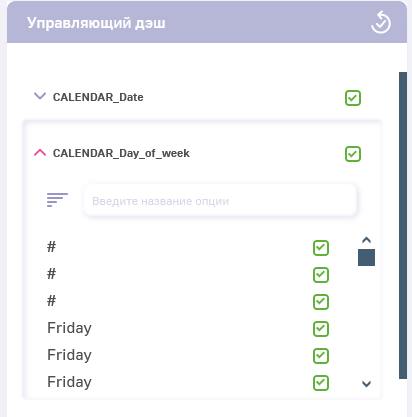
- Это очень интересный пункт. Собрал одну метрику, как вы указали в п.1
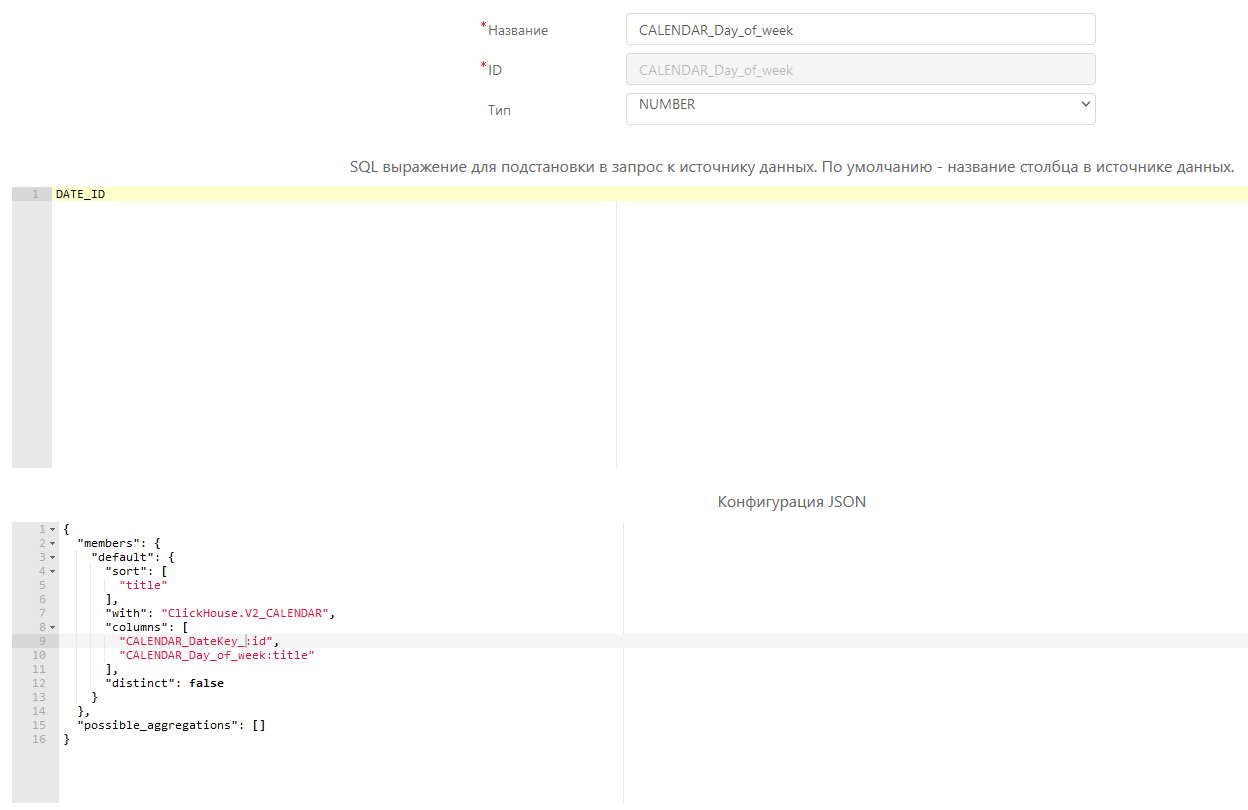
Положил эту метрику в дэш “Таблица”:
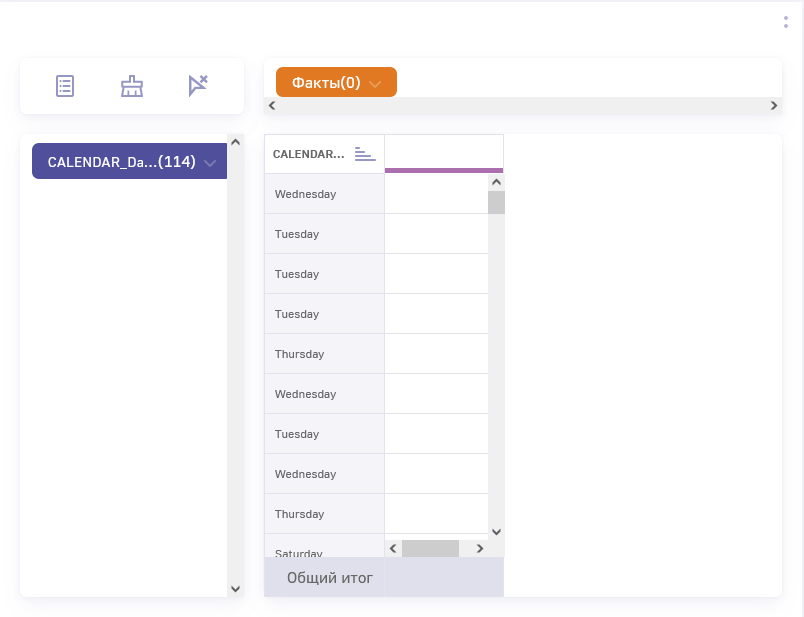
Вижу, что названий дней недели 114. Что-то не то.
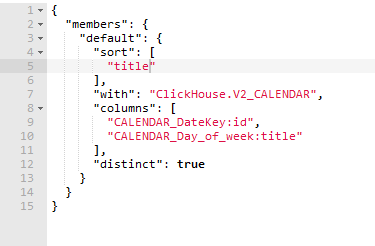
В типовом кубе, который уже существует, эта же метрика выглядит так:
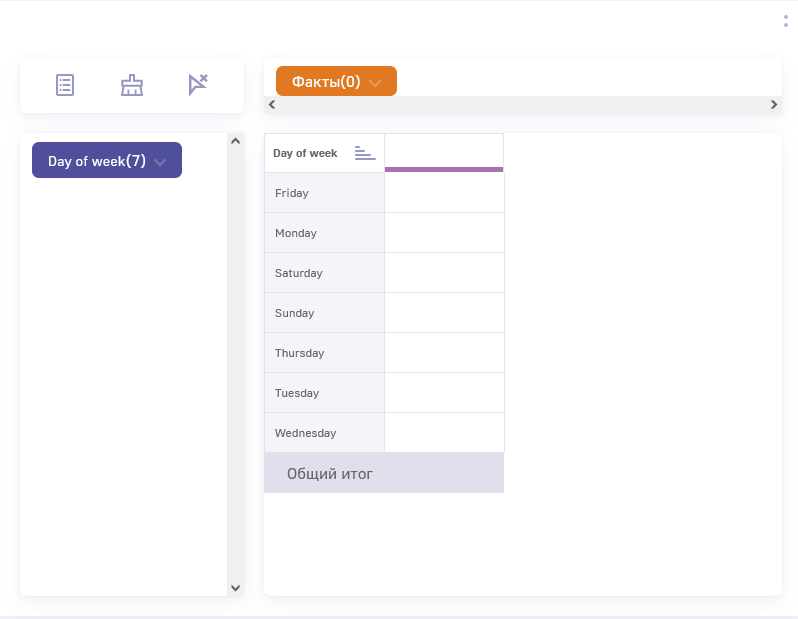
Число названий дней недели 7. Выглядит правильно.
Смотрю запрос, который генерирует таблица с новым варианом куба:
SELECT DISTINCT CALENDAR_DateKey as id, "CALENDAR_Day_of_week" as title
FROM (select *
from date_table) AS V2_CALENDAR
ORDER BY title
Получается, что вместо извлечения атрибута, т.е. только value (“CALENDAR_Day_of_week”) из дочернего куба V2_CALENDAR извлекается пара id/value (CALENDAR_DateKey / “CALENDAR_Day_of_week”). Как следствие, не происходит группировка по полю value.
Какие необходимо сделать настроки, чтобы стала возможна группировка значений в дэшах по value из куба измерения?
.
3. Проверил генерацию запросов к источнику данных с ключом “distinct”: true, с “distinct”: false и совсем без него. При любом варианте запрос остаётся одинаковым. Подскажите, на что влияет данный ключ?
3 - По умолчанию distinct считается как true . Да , тоже наблюдаем этот момент( при указании “distinct”: false в запрос все равно подставляется distinct). Будем разбираться , спасибо за замечание
.
2. Какие необходимо сделать настроки, чтобы стала возможна группировка значений в дэшах по value из куба измерения?
Сможете дать уточнение по этому вопросу?
2 Изначально данный функционал разрабатывался для того , чтобы подключать справочники без написания джоинов . Сейчас “джоин” происходит на стороне веб клиента , т.е в числовое id (которое завязано на id справочника) из целевого куба подставляются значения из справочника, соответственно group by здесь не получится сделать , отсюда и дублирование в приведенном вами примере. В планах есть добавление функционала по генерации джоинов на лету, чтобы была возможность группировки по столбцу(-ам), по срокам не могу подсказать сейчас
Раскройте пожалуйста более подробно данный вопрос.
Также подскажите “hierarchyType”: “parallel”, что выполняет данный атрибут?
Подскажите инструкцию, в которой он прописан.
Описание работы атрибута можно посмотреть по ссылке: https://help.luxmsbi.com/-704
Имелся в виду этот скриншот:
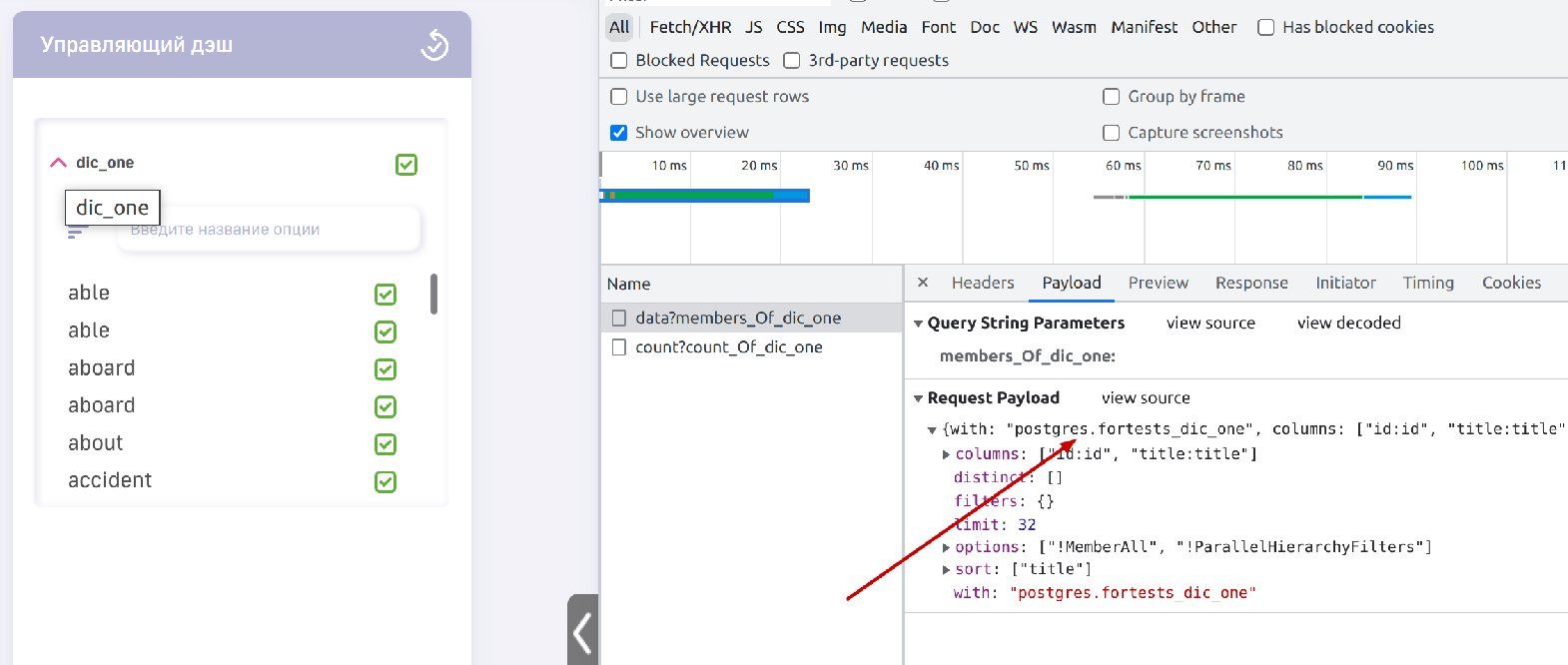
Как я понял, ответ на мой вопрос вопрос такой: да, для архитектуры текущих справочников событие setKoobFilters будет идентично выбору значений в управляющем дэше.