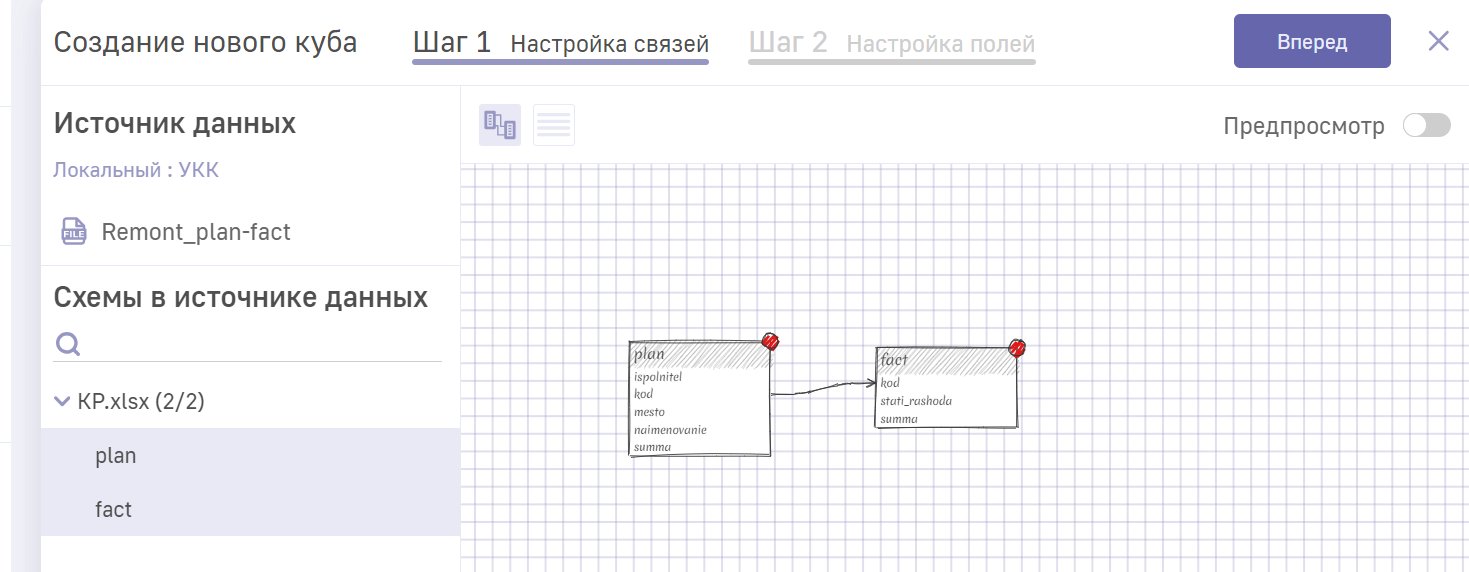
Добрый день! Экспериментируем в песочнице , при создании куба из xls-файла столкнулись с некорректным сопоставлением по полю Код.
пример получившегося дэшборда https://sandbox.demo.luxmsbi.com/#/ds/ds_6/dashboards?dboard=4 по кубу KR_plan-fact.
Куб строился на основании источника данных, аналогичного с Remont_plan_fact.
Повторно построен на тех же данных новый куб Remontplanfact2: связь между данными с листов plan и fact осуществляется по полю kod (int).
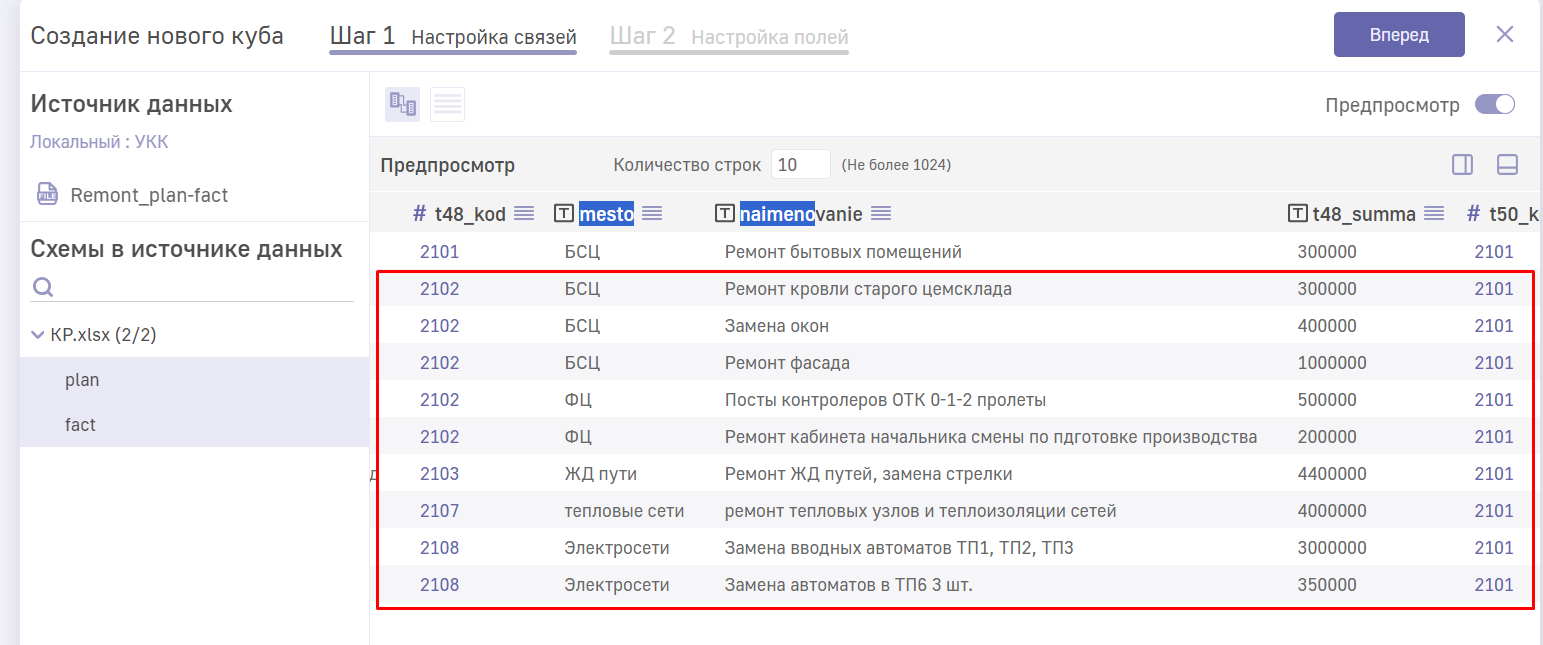
на предпросмотре куба видно, что коду с листа plan (t48_kod) сопоставлены все подряд значения связанного поля код (t50_kod) с листа fact
Просим пояснить, как связать данные источники в схеме, чтобы определенному коду на листе plan соответствовал такой же код на листе fact. Возможно, требуется предварительное суммирование или ещё какие-то группировки?
Правильно ли мы понимаем, что вы хотите добиться уникальности по первому столбцу?
Приведите пример, в каком виде вы ожидаете увидеть таблицу после объединения.
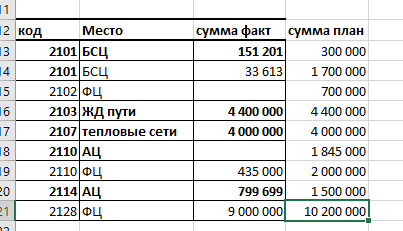
добрый день! да. плюс второй вариант более сложный - сопоставление не только по коду, но и по месту.
видимо, для листа plan нужно промежуточное суммирование, но непонятно, как лучше его провести. Если на этапе ETL сразу суммировать данные по нужным группам, то данные, на основании которых строятся кубы, будут в обобщенном виде, но тогда теряется возможность drill down, чтобы провалиться детально до исполнителей или других детальных составляющих суммы по коду / месту.
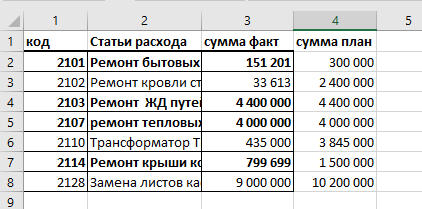
пример сопоставленных данных в обоих случаях:
сопоставление только по коду
Для первого случая - вам необходимо в “from” прописать left join по обеим столбцам. Для второго случая - потребуется дополнительный join по столбцу “Место”.